
学习自@双木的木。
问题描述
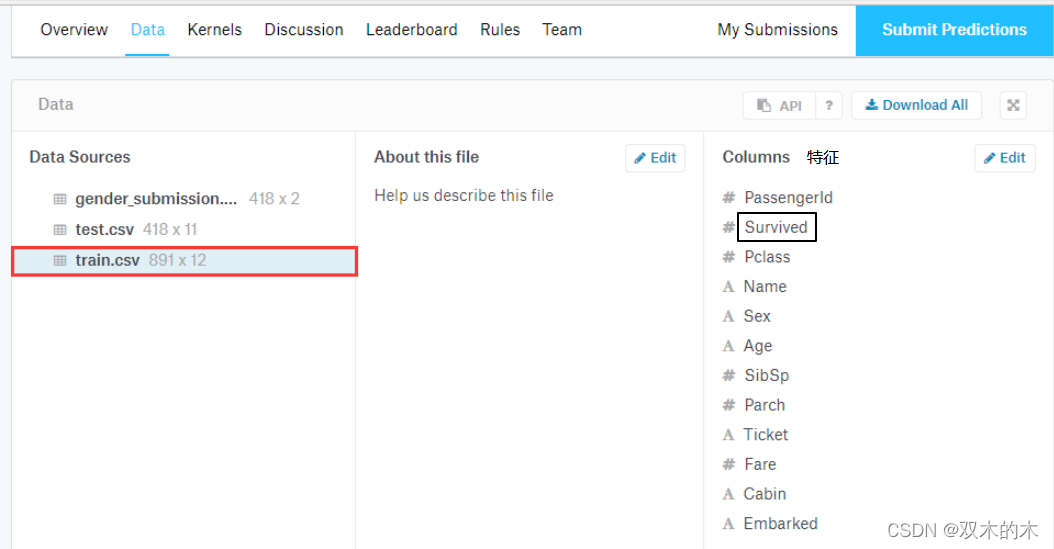
在kaggle官网上有Titanic有关的数据集,有以下features,现要求对Suvrived特征进行预测。
数据集分析
数据集被划分为训练集和测试集:
- training set (train.csv)
- test set (test.csv)
训练集应该被用来建立你的深度学习模型。对于训练集,我们为每个乘客提供结果(也称为“ground truth”)。你的模型将基于乘客的性别和阶级等“特征”。您还可以使用特征工程来创建新的特征。
测试集应该用来查看您的模型在不可见数据上的性能。对于测试集,我们不为每个乘客提供基本真相。你的工作就是预测这些结果。对于测试中的每一位乘客,使用你训练的模型来预测他们是否在泰坦尼克号沉没时幸存下来。
还包括gender_submit .csv,这是一组假设所有且只有女性乘客能够存活的预测,作为提交文件的示例。

选取["Pclass", "Sex", "SibSp", "Parch", "Fare"]五个特征进行训练。
模型
加载数据集
TitanicDataset
class TitanicDataset(Dataset):
def __init__(self, filepath):
features = ["Pclass", "Sex", "SibSp", "Parch", "Fare"]
xy = pd.read_csv(filepath)
self.len = xy.shape[0] # [0]代表行数,[1]代表列数
# dummies相当于one-hot编码
self.x_data = torch.from_numpy(np.array(pd.get_dummies(xy[features], dtype=np.float32))).float()
# np.array(data['survived'])是对data['survived']创建一个矩阵
# torch.from_numpy()是将括号内的矩阵形式转换为张量形式,方便torch处理
self.y_data = torch.from_numpy(np.array(xy['Survived'], dtype=np.float32)).float()
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
titanic_train = TitanicDataset(r'./titanic/train.csv')
train_loader = DataLoader(dataset=titanic_train, batch_size=16, shuffle=True, num_workers=2)构造模型
class Model(torch.nn.Module):
def __init__(self):
# 对继承于torch.nn的父模块类进行初始化
super(Model, self).__init__()
# 这里包括2个线性层,每一个线性层输出都用激活函数激活
self.linear1 = torch.nn.Linear(6, 3) # 五个特征转化为了6维,因为get_dummies将性别这一个特征用两个维度来表示,即男性[1,0],女性[0,1]
self.linear2 = torch.nn.Linear(3, 1)
# 激活函数从Sigmoid这一大类激活函数中选取sigmoid这一种激活函数
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
return x
def verify(self):
val_correct, total = 0, 0
with torch.no_grad():
for i, data in enumerate(train_loader, 0):
inputs, label = data
predicted = model.predict(inputs)
total += label.size(0)
val_correct += (predicted == np.array(label)).sum()
print('Accuracy: %d' %(val_correct / total * 100))
def predict(self, x):
# 该函数用在测试集过程,因此只有前馈,没有什么
with torch.no_grad():
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
y = []
for result in x:
if result > 0.5:
y.append(1)
else:
y.append(0)
return y
model = Model()损失函数和优化器
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)训练模型
if __name__ == '__main__':
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
inputs, label = data
y_pred = model(inputs)
y_pred = y_pred.squeeze(-1) # 将维度降至1维并输出出来
loss = criterion(y_pred, label) # 将预测的值与标签进行比较,并求解出误差值
print(epoch, i, loss.item())
optimizer.zero_grad() # 之前的梯度进行清零,否则梯度会累加起来
loss.backward() # 反向传播
optimizer.step() # 更新验证模型
def verify(self):
val_correct, total = 0, 0
with torch.no_grad():
for i, data in enumerate(train_loader, 0):
inputs, label = data
predicted = model(inputs)
total += label.size(0)
val_correct += (predicted == label).sum().item()
print('Accuracy: %d %%' %(val_correct / total * 100))
model.verify()测试模型
def predict(self, x):
# 该函数用在测试集过程,因此只有前馈,没有什么
with torch.no_grad():
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
y = []
for result in x:
if result > 0.5:
y.append(1)
else:
y.append(0)
return y
test_data = pd.read_csv(r'./titanic/test.csv')
features = ["Pclass", "Sex", "SibSp", "Parch", "Fare"]
test = torch.from_numpy(np.array(pd.get_dummies(test_data[features]), dtype=np.float32))
result = model.predict(test)
submission = pd.read_csv(r'./titanic/gender_submission.csv')
submission['Survived'] = result
submission.to_csv(r'./titanic/gender_submission_result_1.csv', index=False)


Comments | NOTHING